oracle 四分位函数,Oracle分析函数四 |
您所在的位置:网站首页 › oracle 中位数函数 › oracle 四分位函数,Oracle分析函数四 |
oracle 四分位函数,Oracle分析函数四
|
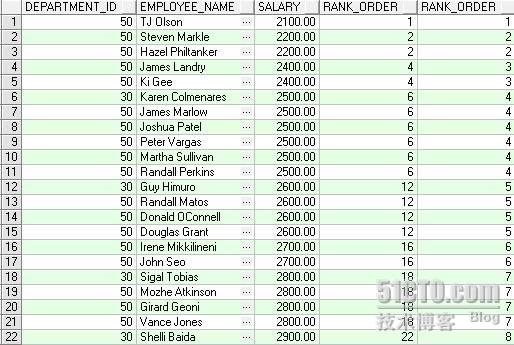
Oracle 分析函数——函数RANK,DENSE_RANK,FIRST,LAST… RANK 功能描述:根据 ORDER BY 子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按 ORDER BY 子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从 1 开始,往后累加。每次 ORDER BY 表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为 null 时相等的)。然而,如果两行的确得到同样的排序,则序数将随后跳跃。若两行序数为 1 ,则没有序数 2 ,序列将给组中的下一行分配值 3 , DENSE_RANK 则没有任何跳跃。 SAMPLE :下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与 DENSE_RANK 函数的区别) DENSE_RANK 功能描述:根据 ORDER BY 子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按 ORDER BY 子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从 1 开始,往后累加。每次 ORDER BY 表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为 null 时相等的)。密集的序列返回的时没有间隔的数 SAMPLE :下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与 RANK 函数的区别) SELECT department_id, first_name||' '||last_name employee_name, salary, RANK() OVER (ORDER BY salary) AS RANK_ORDER, DENSE_RANK() OVER (ORDER BY salary) AS DENSE_RANK_ORDER FROM employees
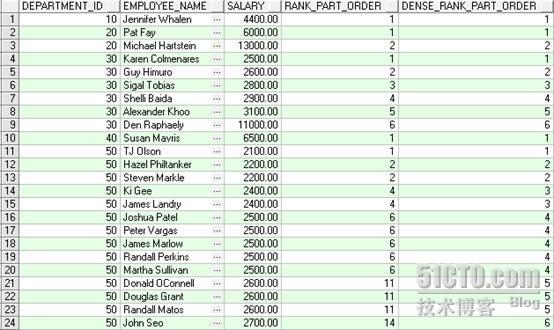
SELECT department_id, first_name||' '||last_name employee_name, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary) AS RANK_PART_ORDER, DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary) AS DENSE_RANK_PART_ORDER FROM employees
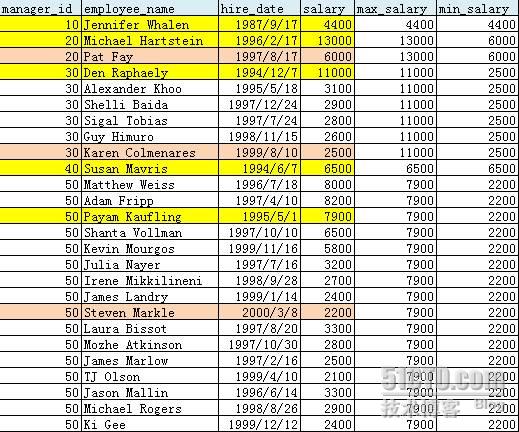
FIRST 功能描述:从 DENSE_RANK 返回的集合中取出排在最前面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录 SAMPLE :下面例子中 DENSE_RANK 按部门分区,再按佣金 commission_pct 排序, FIRST 取出佣金最低的对应的所有行,然后前面的 MAX 函数从这个集合中取出薪水最低的值; LAST 取出佣金最高的对应的所有行,然后前面的 MIN 函数从这个集合中取出薪水最高的值 LAST 功能描述:从 DENSE_RANK 返回的集合中取出排在最后面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录 SAMPLE :下面例子中 DENSE_RANK 按雇用日期排序, FIRST 取出 salary 最低的对应的所有行,然后前面的 MAX 函数从这个集合中取出薪水最低的值; LAST 取出雇用日期最高的对应的所有行,然后前面的 MIN 函数从这个集合中取出薪水最高的值 SELECT department_id, first_name||' '||last_name employee_name, hire_date, salary, MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY hire_date) OVER (PARTITION BY department_id) "Worst", MAX(salary) KEEP (DENSE_RANK LAST ORDER BY hire_date) OVER (PARTITION BY department_id) "Best" FROM employees
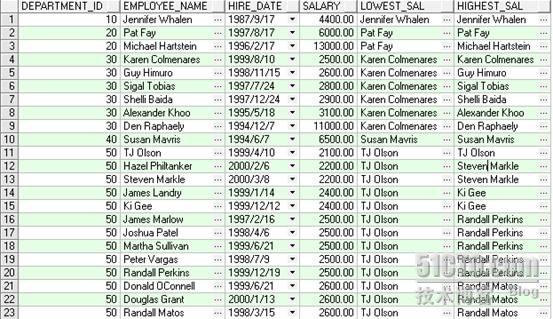
FIRST_VALUE 功能描述:返回组中数据窗口的第一个值。 SAMPLE :下面例子计算按部门分区按薪水排序的数据窗口的第一个值对应的名字,如果薪水的第一个值有多个,则从多个对应的名字中取缺省排序的第一个名字 LAST_VALUE 功能描述:返回组中数据窗口的最后一个值。 SAMPLE :下面例子计算按部门分区按薪水排序的数据窗口的最后一个值对应的名字,如果薪水的最后一个值有多个,则从多个对应的名字中取缺省排序的最后一个名字 SELECT department_id, first_name||' '||last_name employee_name, hire_date, salary, FIRST_VALUE(first_name||' '||last_name) OVER (PARTITION BY department_id ORDER BY salary ASC ) AS lowest_sal, LAST_VALUE(first_name||' '||last_name) OVER(PARTITION BY department_id ORDER BY salary) AS highest_sal FROM employees
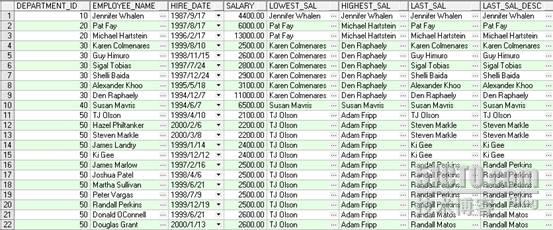
看起来 last_value 和 first_value 的标准似乎有些不一样,不过单独执行就很清楚了,呵呵 SELECT department_id, first_name||' '||last_name employee_name, hire_date, salary, FIRST_VALUE(first_name||' '||last_name) OVER(PARTITION BY department_id ORDER BY salary ) AS lowest_sal, FIRST_VALUE(first_name||' '||last_name) OVER(PARTITION BY department_id ORDER BY salary DESC) AS highest_sal, LAST_VALUE(first_name||' '||last_name) OVER(PARTITION BY department_id ORDER BY salary ) AS last_sal, LAST_VALUE(first_name||' '||last_name) OVER(PARTITION BY department_id ORDER BY salary DESC) AS last_sal_desc FROM employees
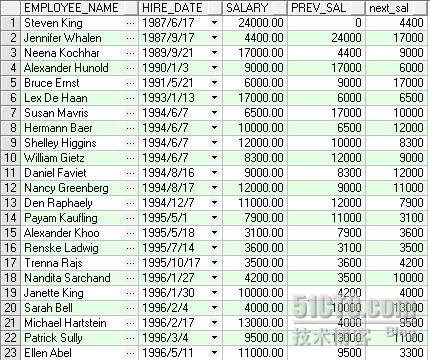
LAG 功能描述:可以访问结果集中的其它行而不用进行自连接。它允许去处理游标,就好像游标是一个数组一样。在给定组中可参考当前行之前的行,这样就可以从组中与当前行一起选择以前的行。 Offset 是一个正整数,其默认值为 1 ,若索引超出窗口的范围,就返回默认值(默认返回的是组中第一行),其相反的函数是 LEAD SAMPLE :下面的例子中列 prev_sal 返回按 hire_date 排序的前 1 行的 salary 值 LEAD 功能描述: LEAD 与 LAG 相反, LEAD 可以访问组中当前行之后的行。 Offset 是一个正整数,其默认值为 1 ,若索引超出窗口的范围,就返回默认值(默认返回的是组中第一行) SAMPLE :下面的例子中列 prev_sal 返回按 hire_date 排序的后 1 行的 salary 值 SELECT first_name||' '||last_name employee_name, hire_date, salary, LAG(salary, 1, 0) OVER (ORDER BY hire_date) AS prev_sal, LEAD(salary, 1,0) OVER (ORDER BY hire_date) AS "next_sal" FROM employees
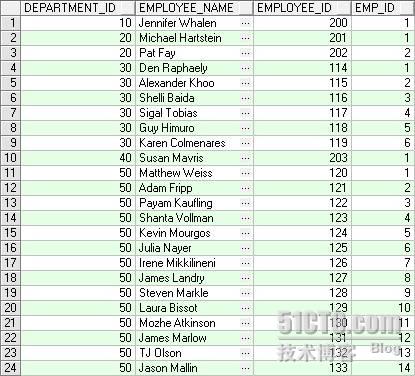
ROW_NUMBER 功能描述:返回有序组中一行的偏移量,从而可用于按特定标准排序的行号。 SAMPLE :下例返回每个员工再在每个部门中按员工号排序后的顺序号 SELECT department_id, first_name||' '||last_name employee_name, employee_id, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_id) AS emp_id FROM employees
|
【本文地址】
今日新闻 |
推荐新闻 |